

This article is part of a series on how to setup a bare-metal CI system for Linux driver development. Here are the different articles so far:
- Part 1: The high-level view of the whole CI system, and how to fully control test machines remotely (power on, OS to boot, keyboard/screen emulation using a serial console);
- Part 2: A comparison of the different ways to generate the rootfs of your test environment, and introducing the Boot2Container project;
- Part 3: Analysis of the requirements for the CI gateway, catching regressions before deployment, easy roll-back, and netbooting the CI gateway securely over the internet.
- Part 4: Generating a live-upgradable operating system image that can also be baked into a container for ease of use.
Now that we have a way to netboot and live-update our CI gateway, it is time to start working on the services that will enable sharing the test machines to users!
This work is sponsored by the Valve Corporation.
Introduction
Test machines are a valuable resource for any organization, may it be from a tech giant or a small-scale open source project. Along with automated testing, they are instrumental to keeping the productivity of developers high by shifting focus from bug fixing to code review, maintenance improvements, and developing new features. Given how valuable test machines are, we should strive towards keeping the machine utilization as high as possible. This can be achieved by turning the developer-managed test machines which show low utilization into shared test machine.
Let’s see how!
Designing the services needed to time-share your test machines
Efficient time-sharing of machines comes with the following high-level requirements:
- Ability to select which hardware you need for your testing;
- Ability to deploy the wanted test environment quickly and automatically;
- Full isolation between testing jobs (no persistent state);
- Bi-directional file-sharing between the testing client and the test machine / device under test (DUT);
- Caching resources to speed up the test machines’ set-up/boot time;
- Real time feedback from / serial console to the test machine.
Let’s review them and propose services that should be hosted on the CI gateway to satisfy them, with backwards-compatibility kept in mind at all time.
Note: This post can be very confusing as it tries to focus on the interaction between different services without focusing on implementation details for the service. To help support my (probably confusing) explanations, I added sequence diagrams when applicable.
So, please grab a pot of your favourite stimulating beverage before going further. If this were to be still insufficient, please leave a comment (or contact me by other means) and I will try my best to address it :)
Boot2container provides transport, deployment, isolation, and caching of test environments
![]()
As we have seen in Part 2, using containers to run test jobs is an effective way to allow any job to set whatever test environment they desire while providing isolation between test jobs. Additionally, it enables caching the test environments so that they do not have to get re-downloaded every time.
This container could be booted using the initramfs we created in part 2, Boot2container, which runs any list of container, as specified in the kernel cmdline.
iPXE & MinIO provide kernel/Boot2Container deployment and configuration

To keep things simple, stateless, and fast, the kernel/Boot2Container binaries and the kernel cmdline can be downloaded at boot time via HTTP by using, for example, iPXE. The iPXE binary can itself be netbooted by the machine’s firmware (see PXE, and TFTP), or simply flashed onto the test machine’s drive/attached USB pen-drive.
The iPXE binary can then download the wanted boot script from an HTTP Server, passing in the query URL the MAC address of the network interface that first got an IP address along with the architecture/platform (PCBIOS, x64 UEFI, …). This allows the HTTP server to serve the wanted boot script for this machine, which contain the URLs of the kernel, initramfs, and the kernel command line to be used for the test job.
Note: While any HTTP server can be used used to provide the kernel and Boot2Container to iPXE, I would recommend using an S3-compatible service such as MinIO as it not only acts like an HTTP server, but also provides an industry-standard interface to manage the data (bucket creation, file uploads, access control, …). This gives you the freedom to change where the service is located and which software provides it without impacting other components of the infrastructure.
Boot2container volumes & MinIO provide file-sharing and user-data caching
Job data caching and bi-directional file-sharing with the test container can be implemented using volumes and Boot2Container’s ability to mirror volumes from/to an S3-compatible cloud storage system such as MinIO (see b2c.volume).
Since this may be a little confusing, here are a couple of examples:
Bidirectional data sharing
Test machines are meant to produce test results, and often need input data before executing tests. An effective solution is to share a folder between the test machine and the machine submitting the job. We suggest using an S3-compatible bucket to share this data, as it provides an industry-standard way of dealing with file between multiple machines.
As an example of how this would look like in practice, here are the operations Boot2Container would need to do in order to start an interactive shell on Alpine Linux on a test machine, with bi-directional data sharing:

- Connect to an S3-compatible Storage, which we name
local_minio; - Create a volume named
job-volume, set the mirror target tolocal_minio’sjob-bucketbucket, then tell to download the content of this bucket right after boot (pull_on=pipeline_start), upload all the content of the volume back to the bucket before shutting down (push_on=pipeline_end), then mark it for deletion when we are done with execution; - Run Alpine Linux (
docker.io/alpine:latest) in interactive mode (-ti), with our volume mounted at/job.
Here is how it would look in the kernel command line, as actual Boot2Container arguments:
b2c.minio="local_minio,http://ci-gateway:9000,<ACCESSKEY>,<SECRETKEY>"
b2c.volume="job-volume,mirror=local_minio/job-bucket,pull_on=pipeline_start,push_on=pipeline_end,expiration=pipeline_end"
b2c.container="-v job-volume:/job -ti docker://docker.io/alpine:latest"
Other acceptable values for {push,pull}_on are: pipeline_start, container_start, container_end, pipeline_end, and
changes. The latter downloads/uploads new files as soon as they get created/modified.
Caching data across reboots that only certain jobs may access
In some cases, a test machine may require a lot of confidential data which would be impractical to re-download every single time we boot the machine.
Once again, Boot2Container has us covered as it allows us to mark a volume as never expiring (expiration=never),
decrypting the data when downloading it from the bucket (encrypt_key=$KEY), then storing it encrypted using
fscrypt (fscrypt_key=$KEY). This would look something like this:
b2c.minio="local_minio,http://ci-gateway:9000,<ACCESSKEY>,<SECRETKEY>"
b2c.volume="job-volume,mirror=local_minio/job-bucket,pull_on=pipeline_start,expiration=never,encrypt_key=s3-password,fscrypt=7u9MGy[...]kQ=="
b2c.container="-v job-volume:/job -ti docker://docker.io/alpine:latest"
Read up more about these features, and a lot more, in Boot2Container’s README.
MaRS & Sergeant Hartman provide test machine enrollment and DB of available machines/hardware
In the previous section, we focused on how to consistently boot the right test environment, but we also need to make sure we are booting on the right machine for the job!
Additionally, since we do not want to boot every machine every time a testing job comes just to figure out if we have the right test environment, we should also have a database available on the gateway that can link a machine id (MAC address?), a PDU port (see Part 1), and what hardware/peripherals it has.
While it is definitely possible to maintain a structured text file that would contain all of this information, it is also very error-prone, especially for test machines that allow swapping peripherals as maintenance operations can inadvertently swap multiple machines and testing jobs would suddenly stop being executed on the expected machine.
To mitigate this risk, it would be advisable to verify at every boot that the hardware found on the machine is the same as the one expected by the CI gateway. This can be done by creating a container that will enumerate the hardware at boot, generate a list of tags based on them, then compare it with a database running on the CI gateway, exposed as a REST service (the Machine Registration Service, AKA MaRS). If the machine is not known to the CI gateway, this machine registration container can automatically add it to MaRS’s database.
New machines reported to (the) MaRS should however not be directly exposed to users, not until they undergo training to guarantee that:
- They boot reliably;
- The serial console is set properly and reliable;
- The reported list of tags is stable across reboots.

Fortunately, the Sergeant Hartman service is constantly on the look out for new recruits (any machine not deemed ready for service), to subject them to a bootloop to test their reliability. The service will then deem them ready for service if they reach a predetermined success rate (19/20, for example), at which point the test machine should be ready to accept test jobs \o/.
Sergeant Hartman can also be used to perform a sanity check after every reboot of the CI gateway, to check if any of the test machine in the MaRS database has changed while the CI gateway was offline.
Finally, CI farm administrators need to occasionally work on a test machine, and thus need to prevent execution of future jobs on this test machine. We call this operation “Retiring” a test machine. The machine can later be “activated” to bring it back into the pool of test machines, after going through the training sequence.
The test machines’ state machine and the expected training sequence can be seen in the following images:

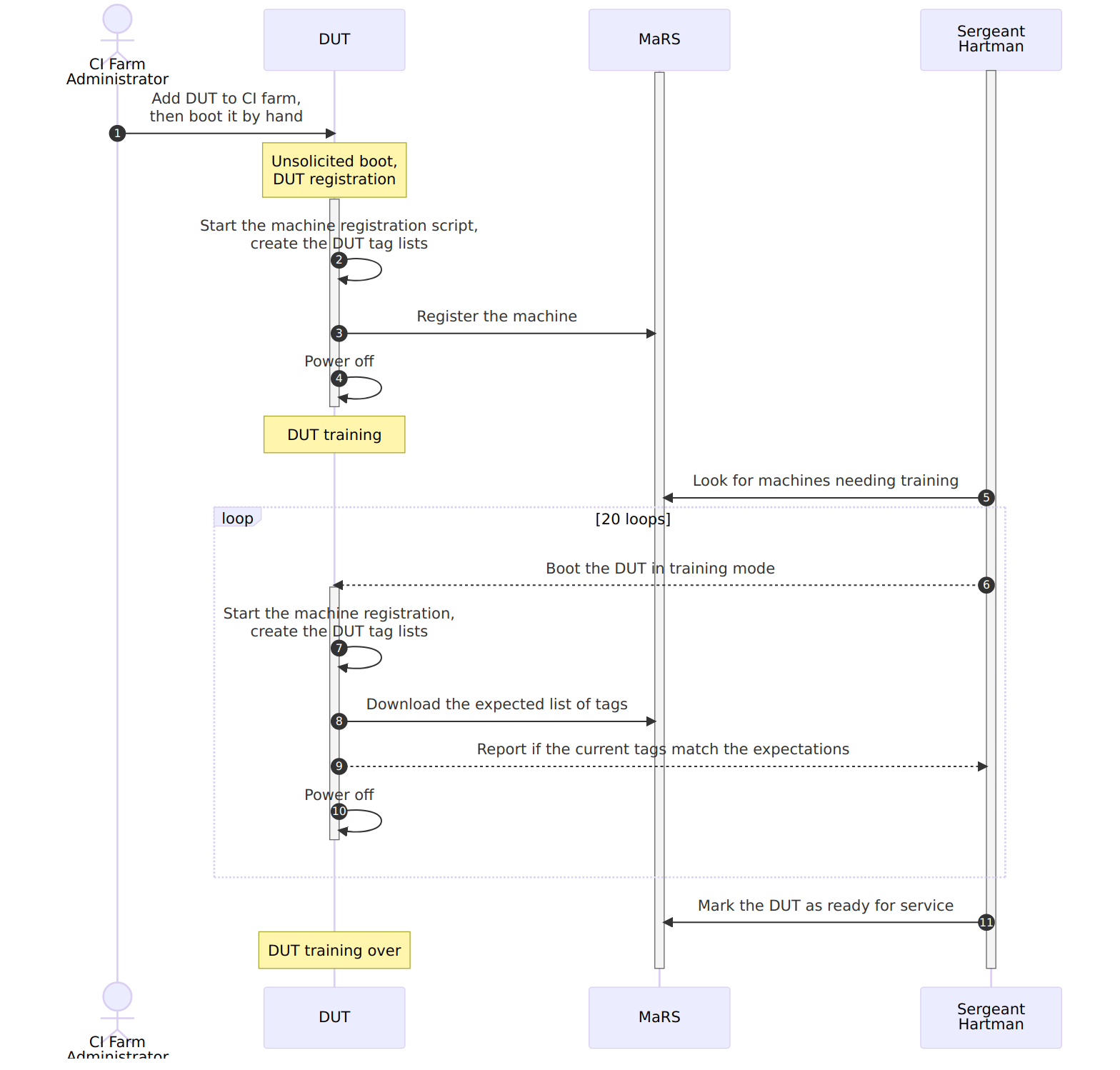
Note: Rebooting test machines booting using the
Boot on ACboot method (see Part 1) may require to be disconnected from the power for a relatively long in order for the firwmare to stop getting power from the power supply. A delay of 30 seconds seems to be relatively conservative, but some machines may require more. It is thus recommended to make this delay configurable on a per-machine basis, and store it in MaRS.
SALAD provides automatic mapping between serial consoles and their attached test machine
Once a test machine is booted, a serial console can provide a real time view of the testing in progress while also enabling users to use the remote machine as if they had an SSH terminal on it.
To enable this feature, we first need to connect the test machine to the CI gateway using serial consoles, as explained in Part 1:
Test Machine <-> USB <-> RS-232 <-> NULL modem cable <-> RS-232 <-> USB Hub <-> Gateway
As the CI Gateway may be used for more than one test machine, we need to figure out which serial port of the test machine is connected to which serial port of the CI gateway. We then need to make sure this information is kept up to date as we want to make sure we are viewing the logs of the right machine when executing a job!
This may sound trivial when you have only a few machines, but this can quickly become difficult to maintain when you have 10+ ports connected to your CI gateway! So, if like me you don’t want to maintain this information by hand, it is possible to auto-discover this mapping at the same time as we run the machine registration/check process, thanks to the use of another service that will untangle all this mess: SALAD.
For the initial registration, the machine registration container should output, at a predetermined baudrate, a
well-known string to every serial port (SALAD.ping\n, for example) then pick the first console port that answers another
well-known string (SALAD.pong\n, for example). Now that the test machine knows which port to use to talk to the CI
gateway, it can send its machine identifier (MAC address?) over it so that the CI gateway can keep track of which serial
port is associated to which machine (SALAD.machine_id=...\n).
As part of the initial registration, the machine registration container should also transmit to MaRS the name of the
serial adapter it used to talk to SALAD (ttyUSB0 for example) so that, at the next boot, the machine can be configured
to output its boot log on it (console=ttyUSB0 added to its kernel command line). This also means that the verification
process of the machine registration container can simply simply send SALAD.ping\n to stdout, and wait for
SALAD.pong\n on stdin before outputing SALAD.machine_id=... to stdout again to make sure the association is still
valid.

On the CI gateway side, we propose that SALAD should provide the following functions:
- Associate the local serial adapters to a test machine’s ID;
- Create a TCP server per test machine, then relay the serial byte stream from the test machine’s serial console to the client socket and vice versa;
- Expose over a REST interface the list of known machine IDs along with the TCP port associated with their machine;
- Create preemptively a test machine/TCP server when asked for the TCP port over the REST interface.
This provides the ability to host the SALAD service on more than just the CI gateway, which may be useful in case the machine runs out of USB ports for the serial consoles.
Here are example outputs from the proposed REST interface:
$ curl -s http://${SALAD_HOST}:${SALAD_PORT}/api/v1/machine/
machines:
"00:d8:61:7a:51:cd":
has_client: false
tcp_port: 48841
"00:e0:4c:68:0b:3d":
has_client: true
tcp_port: 57791
$ curl -s http://${SALAD_HOST}:${SALAD_PORT}/api/v1/machine/00:d8:61:7a:51:cd
has_client: false
tcp_port: 48841
Interacting with a test machine machine’s serial console is done by connecting to the tcp_port associated to the
test machine. In a shell script, one could implement this using curl, jq, and netcat:
$ MACHINE_ID=00:d8:61:7a:51:cd
$ netcat ${SALAD_HOST} $(curl -s http://${SALAD_HOST}:${SALAD_PORT}/api/v1/machine/${MACHINE_ID} | jq ".tcp_port")
# You now have a read/write access to the serial console of the test machine
Power Delivery Unit: Turning ON/OFF your test machines on command
As we explained in Part 1, the only way to guarantee that test jobs don’t interfere with each other is to reset the hardware fully between every job… which unfortunately means we need to cut the power to the test machine long-enough for the power supply to empty its capacitors and stop providing voltage to the motherboard even when the computer is already-off (30 seconds is usually enough).
Given that there are many switchable power delivery units on the market (industrial, or for home use), many communication mediums (serial, Ethernet, WiFi, Zigbee, Z-Wave, …), and protocols (SNMP, HTTP, MQTT, …), we really want to create an abstraction layer that will allow us to write drivers for any PDU without needing to change any other component.
One existing abstraction layer is pdudaemon, which has many drivers for industrial and home-oriented devices. It however does not provide a way to read back the state of a certain port, which prevents verifying that the operation succeeded and makes it difficult to check that the power was indeed off at all time during the mandatory power off period.
The PDU abstraction layer should allow its users to:
- List the supported PDUs / PDU drivers
- Register and validate a PDUs by providing a driver name and any other needed configuration (IP address, …)
- Query the list of registered PDUs, and their ports (label, state, last state change date, power usage, …)
- Set the state of a port, its label, or mark it as reserved / read-only to prevent accidental changes
While this layer could be developed both as a library or a REST service, we would recommend implementing it as a standalone service because it makes the following easier:

- Synchronizing PDU access between clients: required for PDUs using a telnet-/serial-based interface
- Reducing the amount of PDU queries by centralizing all requests in one place, and caching results
- Deploying updates transparently and on-the-fly by running it as a socket-activated systemd service
- Exporting metrics to monitoring systems as a background task (port power consumptions, reboot count, percentage of utilization)
Container registries: Caching containers to reduce bandwidth usage

Even though our test machines cache containers when they first download them, it would still be pretty inefficient if every test machine in the CI farm had to download them directly from the internet.
Rather than doing that, test machines can download the containers through a proxy registry hosted on the CI gateway. This means that the containers will only be downloaded from the internet ONCE, no matter how many test machines you have in your farm. Additionally, the reduced reliance on the internet will improve your farm’s reliability and performance.
Executor: Sequencing the different CI services to time-share test machines
All the different services needed to time-share the test machines effectively have now been described. What we are missing is a central service that coordinates all the others, exposes an interface to describe and queue test jobs, then monitor its progress.
In other words, this service needs to:
- Interface with/implement MaRS/Sergent Hartman to list the test machines available and their state;
- Specify a way for clients to describe jobs;
- Provide an interface for clients to queue jobs;
- Provide exclusive access to a DUT to one job at a time;
- Detect the end of a job or failure, even across reboots by direct messaging from the test machine, or snooping on the serial console;
- Implement watchdogs and retry counters to detect/fix anomalous situations (machine failed to boot, …).
Job description
The job description should allow users of the CI system to specify the test environment they want to use without constraining them needlessly. It can also be viewed as the reproduction recipe in case anyone would like to reproduce the test environment locally.
By its nature, the job description is probably the most important interface in the entire CI system. It is very much like a kernel’s ABI: you don’t want an updates to break your users, so you need to make backwards-compatible changes only to this interface!
Job descriptions should be generic and minimalistic to even have a chance to maintain backwards compatibility. To achieve this, try to base it on industry standards such as PXE, UEFI, HTTP, serial consoles, containers, and others that have proven their versatility and interoperability over the years.
Without getting tangled too much into details, here is the information it should contain:
- The machine to select, either by ID or by list of tags
- The kernel(s) and initramfs to boot
- The kernel command line to use
- The different serial console markers used to detect various conditions and trigger responses
- The different timeouts or watchdogs used
And here are some of the things it should NOT contain:
- Deployment method: DUTs should use auto-discoverable boot methods such as PXE. If the DUT can’t do that natively, flash a small bootloader that will be able to perform this action rather than asking your users to know how to deploy their test environment.
- Scripts: Streaming commands to a DUT is asking for trouble! First, you need to know how to stream the commands (telnet, SSH, serial console), then you need to interpret the result of each command to know when you can send the next one. This will inevitably lead to a disaster either due to mismatching locales, over synchronization which may affect test results, or corrupted characters from the serial console.
Now, good luck designing your job description format… or wait for the next posts which will document the one we came up with!
Job execution
Job execution is split into the following phases:
- Job queuing: The client asks the executor to run a particular job
- Job setup: The executor gathers all the artifacts needed for the boot and makes them accessible to the DUT
- Job execution: The DUT turns on, deploy, executes the test environment, uploads results, then shut down
- Job tear-down: The results from the job get forwarded to the client, before releasing all job resources
While the executor could perform all of these actions from the same process, we would recommend splitting the job execution into its own process as it prevents configuration changes from affecting currently-running jobs, make it easier to tell if a machine is running or idle, make live-updating the executor trivial (see Part 4 if you are wondering why this would be desirable), and make it easier to implement job preemption in the future.
Here is how we propose the executor should interact with the other services:

Conclusion
In this post, we defined a list of requirements to efficiently time-share test machines between users, identified sets of services that satisfy these requirements, and detailed their interactions using sequence diagrams. Finally, we provided both recommendations and cautionary tales to help you set up your CI gateway.
In the next post, we will take a bit of breather and focus on the maintainability of the CI farm through the creation of an administrator dashboard, easing access to the gateway using a Wireguard VPN, and monitoring of both the CI gateway and the test machines.
By the end of this blog series, we aim to have propose a plug-and-play experience throughout the CI farm, and have it automatically and transparently expose runners on GitLab/GitHub. This system will also hopefully be partially hosted on Freedesktop.org to help developers write, test, and maintain their drivers. The goal would be to have a setup time of under an hour for newcomers!
That’s all for now, thanks for making it to the end of this post!